CSE5313 Coding and information theory for data science (Lecture 24)
Continue on coded computing
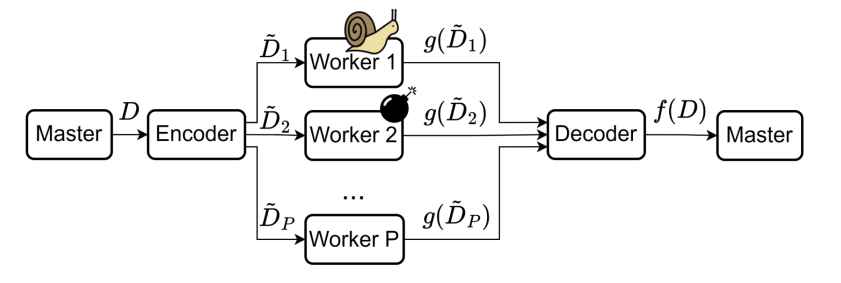
Matrix-vector multiplication: , where
- MDS codes.
- Recover threshold .
- Short-dot codes.
- Recover threshold .
- Every node receives at most . elements of .
Matrix-matrix multiplication
Problem Formulation:
- ,
- are submatrices of .
- We want to compute .
Trivial solution:
- Index each worker node by .
- Worker node performs matrix multiplication .
- Need nodes.
- No erasure tolerance.
Can we do better?
1-D MDS Method
Create by encoding . with some MDS code.
Need worker nodes, and index each one by .
Worker node performs matrix multiplication .
Need responses from each column.
The recovery threshold nodes.
This is trivially parity check code with 1 recovery threshold.
2-D MDS Method
Encode with some MDS code.
Encode with some MDS code.
Need nodes.
Decodability depends on the pattern.
- Consider an bipartite graph (rows on left, columns on right).
- Draw an edge if is missing
- Row is decodable if and only if the degree of ‘th left node .
- Column is decodable if and only if the degree of ‘th right node .
Peeling algorithm:
- Traverse the graph.
- If ,, remove edges.
- Repeat.
Corollary:
- A pattern is decodable if and only if the above graph does not contain a subgraph with all degree larger than .
- (linearly)
- .
- Consider bipartite graph with complete subgraph.
- There exists subgraph with all degrees larger than not decodable.
- On the other hand: Fewer than edges cannot form a subgraph with all degrees .
- scales sub-linearly with .
Our goal is to get rid of .
Polynomial codes
Polynomial representation
Coefficient representation of a polynomial:
- Uniquely defined by coefficients .
Value presentation of a polynomial:
- Theorem: A polynomial of degree is uniquely determined by points.
- Proof Outline: First create a polynomial of degree from the points using Lagrange interpolation, and show such polynomial is unique.
- Uniquely defined by evaluations
Why should we want value representation?
- With coefficient representation, polynomial product takes multiplications.
- With value representation, polynomial product takes multiplications.
Definition of a polynomial code
Problem formulation:
We want to compute .
Define matrix polynomials:
, degree
, degree
where each are matrices
We have
Observe that
if and only if and .
The coefficient of is .
Computing is equivalent to find the coefficient representation of .
Encoding of polynomial codes
The master choose .
- Note that this requires .
For every node , the master computes
- Equivalent to multiplying by Vandermonde matrix over .
- Can be speed up using FFT.
Similarly, the master computes for every node .
Every node computes and returns to the master.
is the evaluation of polynomial at .
Recall that .
- Computing is equivalent to finding the coefficient representation of .
Recall that a polynomial of degree can be uniquely defined by points.
- With evaluations of , we can recover the coefficient representation for polynomial .
The recovery threshold , independent of , the number of worker nodes.
Done.
MatDot Codes
Problem formulation:
-
We want to compute .
-
Unlike polynomial codes, we let and . And .
-
In polynomial codes, and .
Key observation:
is an matrix, and is an matrix. Hence, is an matrix.
Let .
Let , degree .
Let , degree .
Both have degree .
And .
Key observation:
- The coefficient of the term in is .
Recall that .
Finding this coefficient is equivalent to finding the result of .
Here we sacrifice the bandwidth of the network for the computational power.
General Scheme for MatDot Codes
The master choose .
- Note that this requires .
For every node , the master computes and .
- , degree .
- , degree .
The master sends to node .
Every node computes and returns to the master.
The master needs evaluations to obtain .
- The recovery threshold is
Recap on Matrix-Matrix multiplication
, we want to compute with nodes.
Every node receives of and of .
| Code | Recovery threshold |
|---|---|
| 1D-MDS | |
| 2D-MDS | |
| Polynomial codes | |
| MatDot codes |
Polynomial Evaluation
Problem formulation:
- We have datasets .
- Want to compute some polynomial function of degree on each dataset.
- Want .
- Examples:
- are points in , and .
- , both in , and .
- Gradient computation.
worker nodes:
- Some are stragglers, i.e., not responsive.
- Some are adversaries, i.e., return erroneous results.
- Privacy: We do not want to expose datasets to worker nodes.
Replication code
Suppose .
- Partition the nodes to groups of size each.
- Node in group computes and returns to the master.
- Replication tolerates stragglers, or adversaries.
Linear codes
Recall previous linear computations (matrix-vector):
- is the corresponding codeword of .
- Every worker node computes .
- is the corresponding codeword of .
- This enables to decode from .
However, is a polynomial of degree , not a linear transformation unless .
- , where is a constant.
- .
is not the codeword corresponding to in any linear code.
Our goal is to create an encoder/decode such that:
- Linear encoding: is the codeword of for some linear code.
- i.e., for some generator matrix .
- Every is some linear combination of .
- The are decodable from some subset of ‘s.
- Some of coded results are missing, erroneous.
- ’s are kept private.
Lagrange Coded Computing
Let be a polynomial whose evaluations at are .
- That is, for every .
Some example constructions:
Given with corresponding
- , where .
Then every is an evaluation of polynomial at .
If the master obtains the composition , it can obtain every .
Goal: The master wished to obtain the polynomial .
Intuition:
- Encoding is performed by evaluating at , and for redundancy.
- Nodes apply on an evaluation of and obtain an evaluation of .
- The master receives some potentially noisy evaluations, and finds .
- The master evaluates at to obtain .
Encoding for Lagrange coded computing
Need polynomial such that:
- for every .
Having obtained such we let for every .
.
Want for every .
Tool: Lagrange interpolation.
- .
- and for every .
- .
Let .
- .
- for every .
Let .
Every is a linear combination of .
This is called a Lagrange matrix with respect to
- . (interpolation points)
- . (evaluation points)
Continue next lecture