CSE510 Deep Reinforcement Learning (Lecture 19)
Model learning with high-dimensional observations
- Learning model in a latent space with observation reconstruction
- Learning model in a latent space without reconstruction
Learn in Latent Space: Dreamer
Learning embedding of images & dynamics model (jointly)
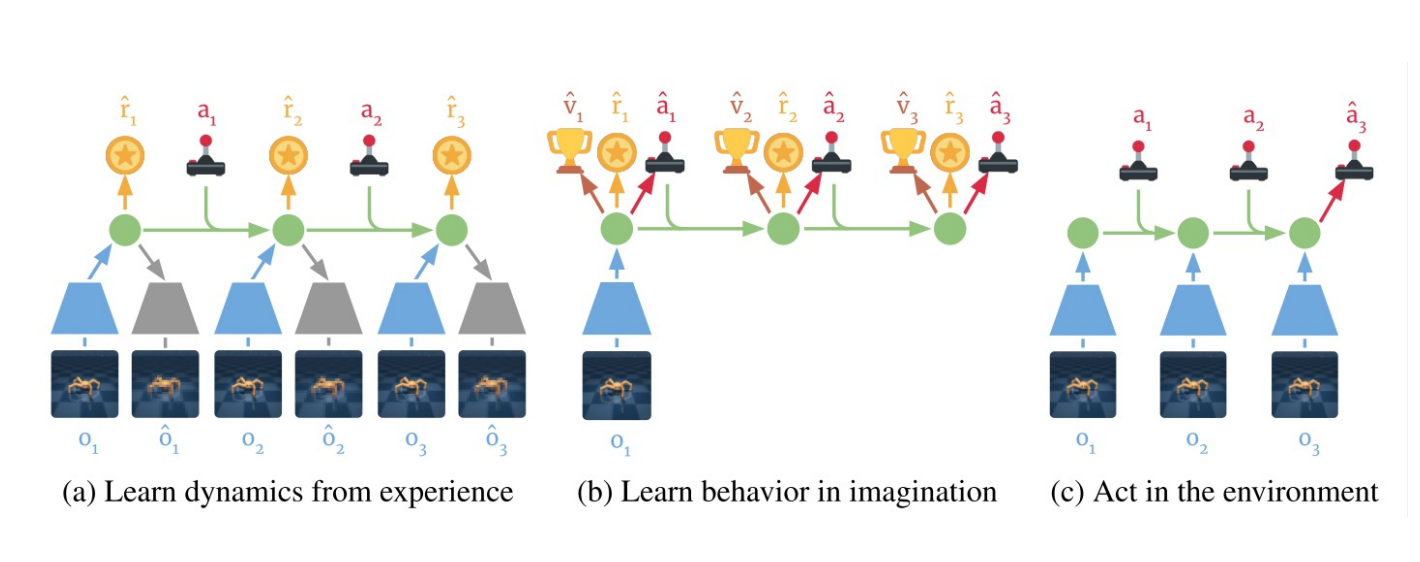
Representation model:
Observation model:
Reward model:
Transition model: .
Variational evidence lower bound (ELBO) objective:
where
More versions for Dreamer
Latest is V3, link to the paper
Learn in Latent Space
- Pros
- Learn visual skill efficiently (using relative simple networks)
- Cons
- Using autoencoder might not recover the right representation
- Not necessarily suitable for model-based methods
- Embedding is often not a good state representation without using history observations
Planning with Value Prediction Network (VPN)
Idea: generating trajectories by following -greedy policy based on the planning method
Q-value calculated from -step planning is defined as:
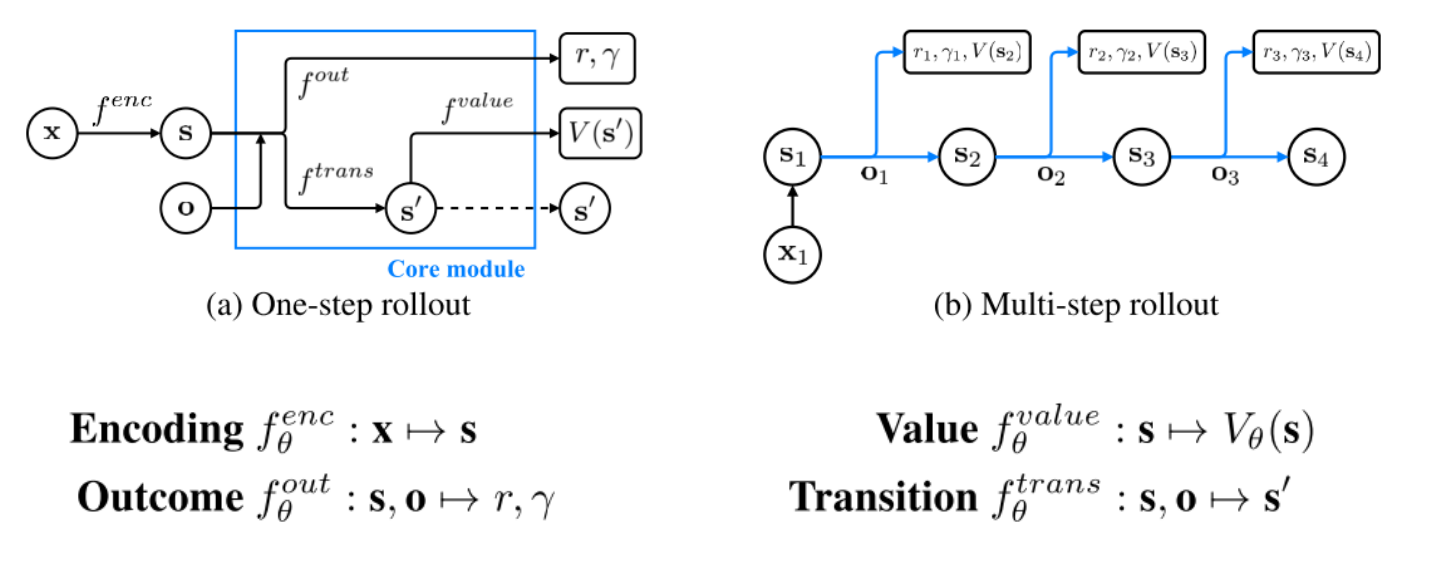
Given an n-step trajectory generated by the -greedy policy, k-step predictions are defined as follows:
MuZero
beats AlphaZero
Last updated on